


Intuiting Latency and Throughput
Although they may seem highly technical, you've already experienced both concepts - and why they matter - if you've ever done a load of laundry.
This is the twelfth video in Part 3 of the Performance-Aware Programming series. Please see the Table of Contents to quickly navigate through the rest of the course as it is updated weekly.
We've reached the point in the Performance-Aware Programming Course where we will be talking about latency and throughput a lot. These are concepts we've seen a in passing already, but we've never really talked in detail about what they mean — more importantly, we haven't had a chance to build an intuition for what they mean.
So now that we're getting into the nitty-gritty of how CPUs process instructions, I wanted to give you an intuitive explanation of latency and throughput so that anyone who's not familiar with those concepts, or hasn't had a chance to internalize them, has a solid foundation to start with.
The way I'd like to do this is by talking about laundry. Hopefully you have at least some experience with doing laundry?
Specifically, I want to talk about the kind of laundry setup some homes have where there is a washer and a dryer — two separate machines, one that washes the clothes, one that dries them.
The idea here is that you put a load of laundry into the washer, it swirls around for an hour, and then your clothes are washed, but damp. You take that load and you move it to the dryer, it tumbles around for an hour, and then your clothes are dry.
That’s a finished load of laundry, and if it takes one hour in each machine, then we would expect one load to take two hours:

Now I'd like you to consider another configuration for the laundry room. Instead of two machines — a washer and a dryer — what if there was just one machine that washed and dried the clothes?
These machines do exist, they’re just less common. You put the laundry in a single cylindrical compartment. The machine fills with water and spins the clothes around for an hour, just like it was a washer. But then, it drains the water out, and heats the compartment while it tumbles the clothes around for an hour — just like a dryer.
When we think about this “combo” machine, it doesn’t seem much different than the split washer and dryer. It also takes two hours to do a load of laundry, right?

We might even think that the combo machine is more efficient than the split machines — after all, it probably takes some small amount of time to transfer the clothes from a washer to a dryer. The combo machine doesn’t require that transfer.
So even if both cases spend one hour washing and one hour drying, we might naively expect the combo machine to wash clothes slightly faster than the split machines. We certainly wouldn’t expect the split machine to somehow be significantly faster at washing clothes somehow, right?
Well, if you’ve ever done a lot of laundry before, you might intuitively sense something’s wrong with this picture. We’re only considering what happens when we do one load of laundry. Yes, with only one load, both setups seem equivalent. But what happens if we have a lot of laundry to do?
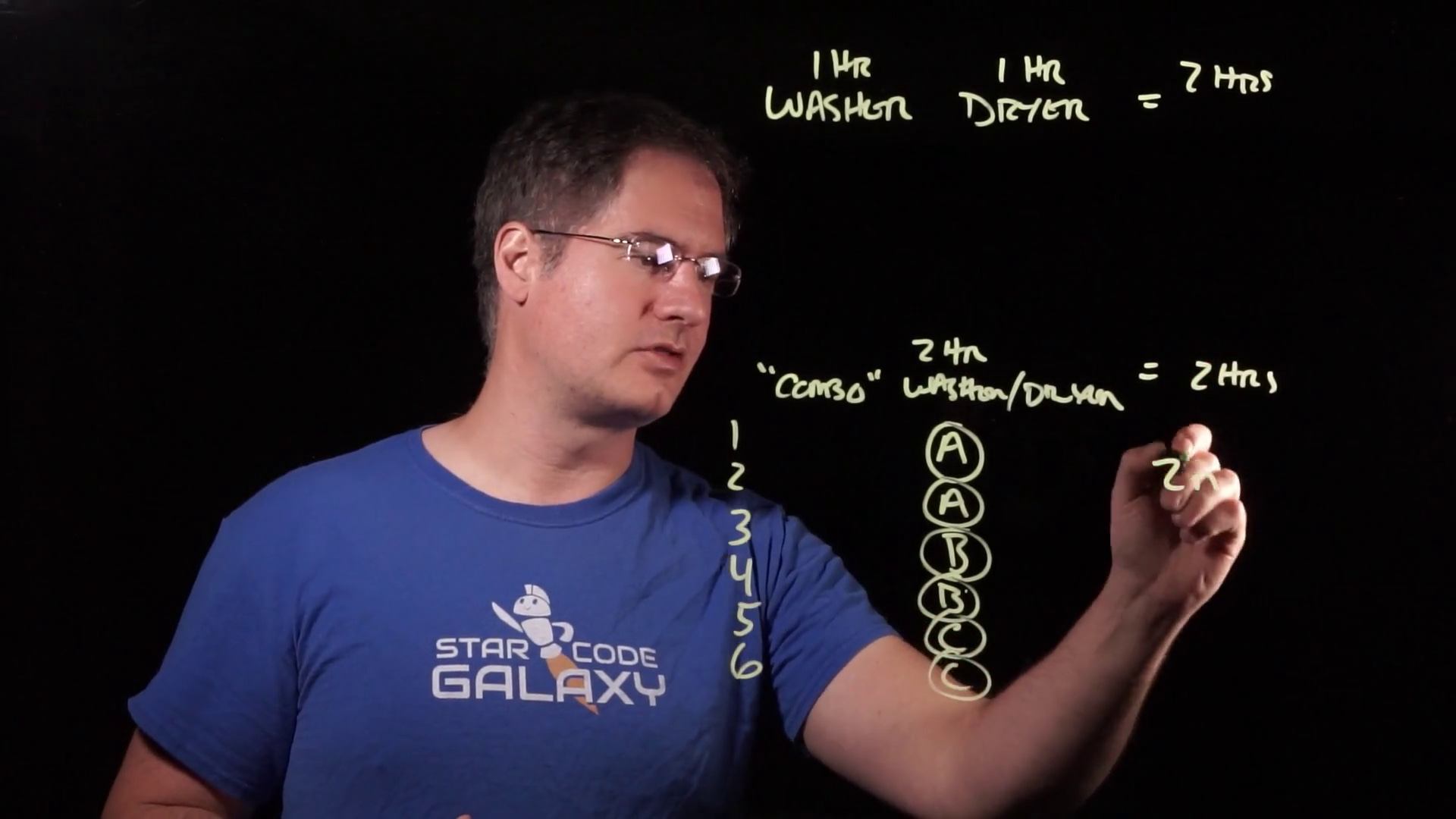
For example, suppose we had three loads of laundry to do — A, B and C. In the combo machine, we put in load A, and wait two hours. Then we take load A out, put in load B, and wait another two hours. Then we do the same with load C:

It takes use six hours to do three loads of laundry. Looking at the pattern, it’s intuitively obvious that to do any number of loads of laundry, it takes twice that number of hours: for n loads, it’s 2n hours:
What happens when we use the split machines?
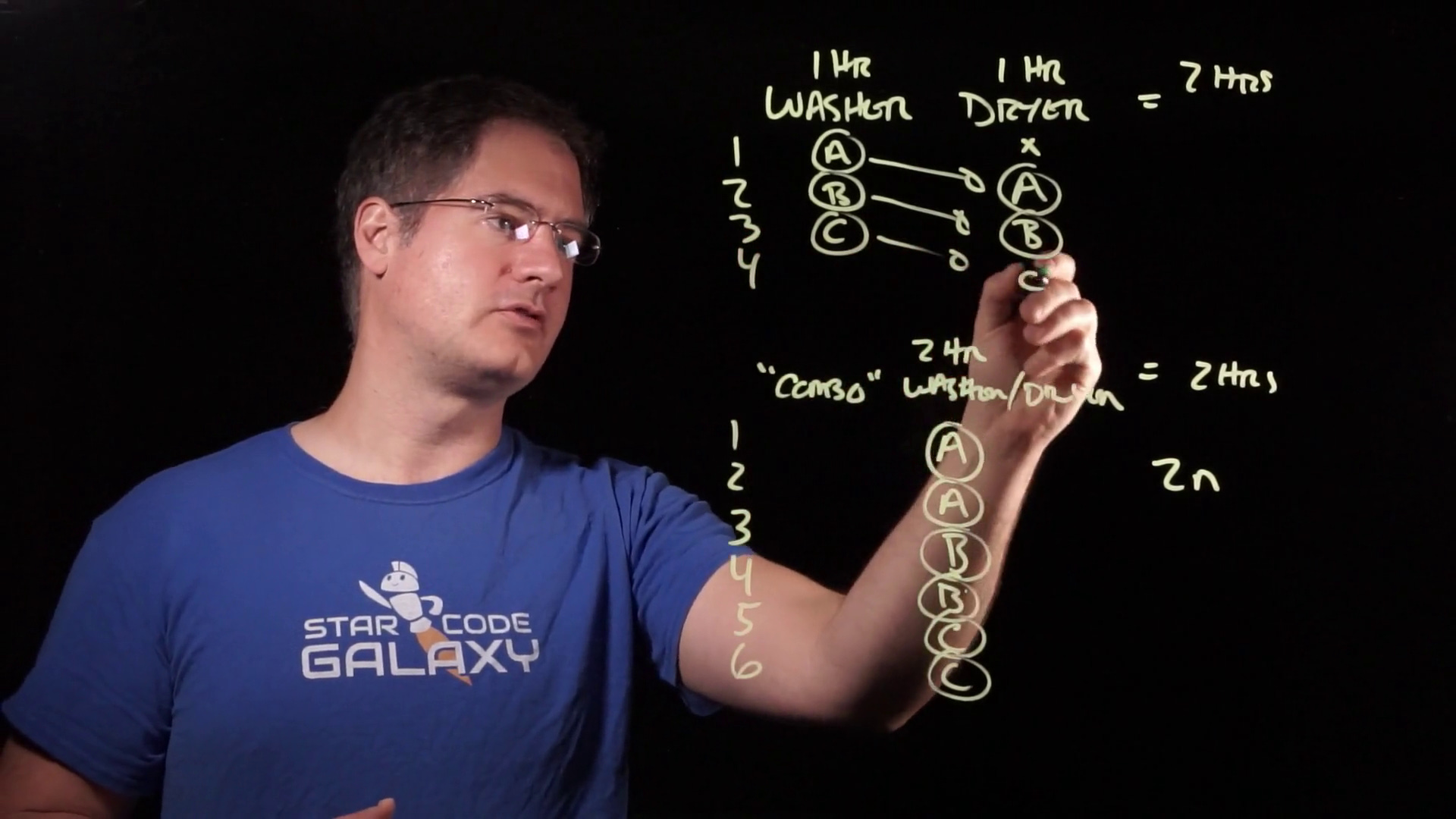
Well, we put load A into the washer, and we wait one hour. This is essentially the same as what happened in the combo case.
But then, when the hour is up, we transfer load A to the dryer:

The washer is now empty. So, instead of waiting another hour to put in load B, we just put it in right away — before load A has even started drying, let alone finished:

We didn’t need a degree in CPU architecture to know to do this. Everyone who does laundry with machines like these does this intuitively.
But this unremarkable process leads to a rather remarkable result. This laundry pipeline allows us to constantly overlap the washing work with the drying work for the entire time we have more laundry to do:
Suddenly, the expected six hours it would take to do three two-hour loads of laundry only takes four hours:
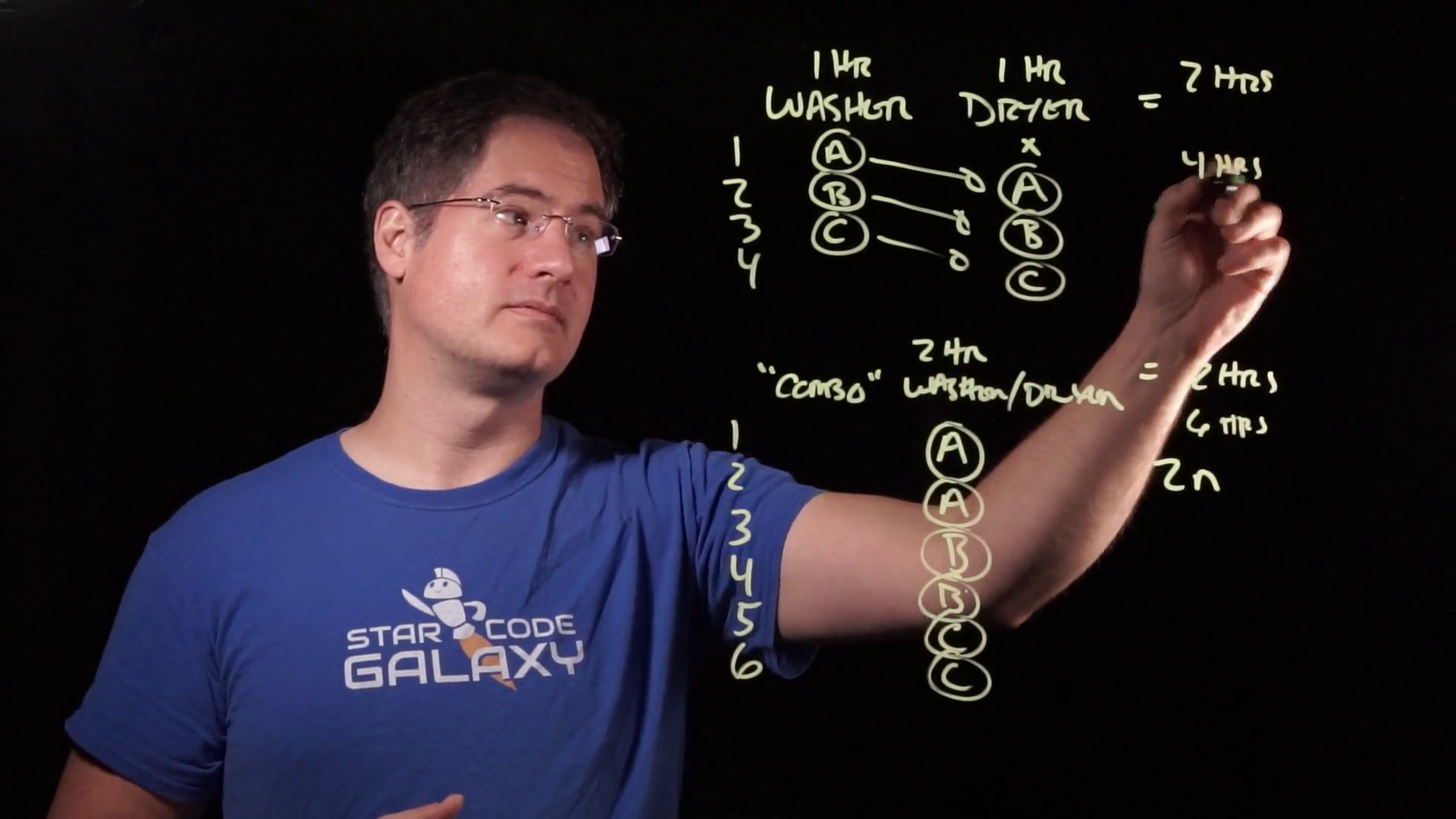
Two of the hours have vanished. Where did they go? They didn’t go anywhere — they just happened at the same time:

Specifically, in the combo case, each hour of laundry only resulted in one hour of work. In the split case, two of the hours did double. The first and fourth hours did only one hour each, since the dryer and washer were left empty, respectively.
But in the second hour of laundry, the machines did two hours of work: the washing of load B and the drying of load A. Similarly, the third hour of laundry was another two hours of work: washing C and drying B.
Instead of taking 2n hours to do n loads of laundry, the split case actually takes just 1+n hours thanks to the washing and drying happening simultaneously for all but the first and last hours.
While this may be a completely unsurprising result for anyone who does a lot of laundry, the principle here is profound: when we split an operation into a sequence of smaller steps, even though the total time it takes to perform the operation stays the same, the time it takes to do that operation repeatedly drops dramatically because steps can now be performed simultaneously.
Which brings us to latency and throughput:

Latency and throughput are measurements we use in performance analysis to summarize the behavior of a CPU pipeline — and, if we’d like, our laundry as well!
Latency is the amount of time it takes to do one entire operation to completion. In our laundry case, this was always two hours. In the combo machine, it took two hours to wash and dry one load of laundry. In the split case, even though it could overlap multiple loads of laundry, that did not change the latency. It still took two hours to wash and dry a load.
Another way to say this is that latency is measuring the time from when a particular load goes into the washer to when it comes out of the dryer. It’s the total time a load spends in the laundry, all steps included. Since it doesn’t matter how much overlap there might be with other loads of laundry, latency does not improve when you can do unrelated work simultaneously.
In other words, if your favorite shirt is dirty, and you want to wear it, it’s going to take two hours to get it washed and dried. Even though we clearly see that the split machines are faster at doing laundry in bulk, there would be no difference between them and the combo machine in the two hour wait time for your favorite shirt. Both configurations have two-hour latency.
Throughput, on the other hand, is a measure of the rate at which you expect operations to complete when the pipeline is operating at full capacity. In a typical hour, how many finished loads of laundry do you expect to receive from the machine? Alternately, you could think of it the other way around, and ask how many loads do you expect to be able to start in a given hour?
In the case of the combo machine, it’s clearly it takes two hours for each load of laundry, no matter how many loads we do. So the number of loads started, or finished, per hour is 1/2, or 0.5 loads/hour.
For the split machines, once the pipeline is going, we expect to get one finished load out every hour. Equivalently, we expect to be able to put one new load in every hour. Therefore, the throughput is 1 load/hour.
But even this simple laundry example illustrates an annoying aspect of latency and throughput: the senses are inverted between the two.
Latency is measured in time per operation. It’s the amount of hours it takes to do a load of laundry, the amount of cycles it takes to do a CPU instruction, and so on. This means it goes up as it gets worse, and down as it gets better — we want our laundry to take less hours to do, we want out CPU instructions to take less cycles. We want lower latency.
Throughput, on the other hand, is measured in operations per unit time. It’s the number of loads per hour, or the number of instructions per cycle:

This is the inverse of latency! It goes down as it gets worse, and up as it gets better. We want our laundry to do more loads per hour, and our CPU to do more instructions per cycle.
To fix this mismatch, in performance analysis, we often talk about throughput as reciprocal throughput instead of regular throughput:

Reciprocal throughput is exactly what it sounds like: it’s 1/throughput, the inverse of the throughput. This turns operations per unit time into time per operation, which aligns it with latency. Now, we can talk about latency and reciprocal throughput together, and keep the same sense — since the units are the same, lower is now better in both, and higher is worse.
Furthermore, it makes the numbers match when the performance matches, which makes the numbers easier to understand at a glance. The combo case is a good example: we know it doesn’t have any work overlap. It takes two hours to do each load always, no matter how full its “pipeline” is. So we would like the two numbers to be equal in this case, so it’s easy to see what’s happening.
With latency and regular throughput, this doesn’t happen. The latency is 2 hours per load, but the throughput is 1/2 loads per hour. These look completely different, even though they’re representing the same performance.
With latency and reciprocal throughput, on the other hand, everything lines up. The latency is still 2 hours per load, and the reciprocal throughput is 1/(1/2 loads per hour), which simplifies to 2 hours per load — exactly the same as the latency.
Now, unfortunately the regular-vs-reciprocal throughput situation gets more confusing when you're reading things on the internet. Often, blog posts or reference materials will omit the “reciprocal” and just say “throughput”. But they don’t really mean throughput, they mean reciprocal throughput. And if you’re not already fluent in these concepts, that can throw you for a loop. So, it’s best to always keep an eye out for this omission! If the numbers being discussed sound like reciprocal throughput, the often are, even if the author says keeps saying “throughput” alone.
So that's latency and throughput, but before we conclude, I’d like to mention another concept implicit in everything we just did: dependency chains.
Even in the simple laundry example, we already have dependency chains, they’re just very short. Where are they? They’re right here:

Each drying step we did was dependent on its corresponding washing step. Intuitively we knew this: we never tried to dry a load of laundry before washing it. A dependency chain is just the formalization of this concept: that some operations are dependent on others, and these dependencies form “chains” of operations where each operation in the chain can only happen when the previous operations have completed.
I didn’t mention it when we first drew this table, but now that we’re talking about dependency chains, there’s a crucial observation here: if it weren’t for the dependency chains, we could have done this work even faster.
How? Well, in the first hour, the dryer is empty. If we didn’t have to wait for clothes to be washed before drying them, we could have moved the drying step of load C up to the first hour, and done it while load A was being washed! That would have reduced the time from four hours to three hours.
So here we see the true nature of latency, and why it is usually slower than throughput: when we have to wait for some earlier work to be done before we can start some later work, we reduce the amount of work than can be done simultaneously. This leads to idle work units — like our dryer in hour one — which leads to slower performance.
In fact, we could also say that the whole reason our split machines had lower (better) reciprocal throughput than latency was because loads of laundry aren’t dependent, so they can be done in simultaneously. If we lived in some weird universe where there was a law of physics requiring you to include a piece of clothing from your most recent load of laundry in each new load of laundry, we wouldn’t be able to use the split machines to do laundry faster! Since we’d have to wait for load A to be washed and dried completely, so we could take an article of clothing from it and put it in load B before we started washing load B, there would be no way to overlap the operations. Our split machines would be relegated to the same poor performance as the combo machine: two hour per load of laundry, period.
Now, this is a lot of concepts to internalize — but hopefully you can understand now that these aren't weird or imaginary things that only occur inside computer hardware. They're all just basic concepts of work and time that arise naturally in the real world. They work the exact same way, whether you’re trying to optimize a piece of code, or streamline your daily routine.
If you have any questions on these concepts, and you're taking my Performance-Aware Programming Course, please be sure to put them in the comment section of the most recent Q&A post. As always, I answer all the new questions every Monday, and the most recent Q&A post is where I look for new questions.
If you're not taking the course, well, this kind of intuition-building is one of the things we do here! We try to take the complexities of modern computer hardware and software, and make it intuitive through exercises, analogies, and explorations. If that sounds interesting to you, you can subscribe here:
The next video in the series will be for subscribers only, and it will expand on the simple example we worked through here. We’ll take this idea of a “dependency chain” and we’ll apply it to a more complex task to see how we would analyze the more complex dependency chains that result. We’ll do it for an everyday task, just like the laundry — but then we’ll translate that into the CPU equivalent, to prepare us for doing CPU performance analysis of real code.
here is a video that shows a real world example of this pipelining idea, and how to increase throughput by doing many things at the same time: https://www.youtube.com/watch?v=CPaNNiB2H-s
This seems like it should be so obvious but for some reason has never really occurred to me: splitting tasks into smaller tasks that can be pipelined improves throughput.
I mean, obviously! That's why CPUs have a pipeline for decoding and executing instructions.
I'm pretty sure I studied this during University but somehow it didn't stick with me because I ended up doing web development in Python and Javascript where no one cares about how the system works under the hood.
So now, given this picture, perhaps the job of a system engineer (or at least one aspect of his job) is to come up with a way to split complex tasks in the system into a series of smaller tasks that can be processed in parallel, have a queue for each task, and assign one CPU Core to it.
So if you have a complex task T that needs to be applied to N items, we can split it into 4 steps, T0, T1, T2, T3 and have each core handle one subtask: take an item from the Ti queue, apply Ti, pass the object to T[i+1] queue.
Hmm. I wonder if memory caching issues introduce complications to the dependency chains. Assuming a shared L2 cache, the system should work fairly well assuming each subtask can start and finish in a timely manner with no delays in moving items from one step in the pipeline to the next.
(Sorry for the all over the place mumbling comment; just thinking out loud).