
Zen, CUDA, and Tensor Cores, Part I: The Silicon

This is part 1 of a miniseries on today’s common consumer computing cores. It contains investigations into undisclosed hardware details. I have tried to validate the accuracy of the series by consulting hardware designers, and have done my best to paint an accurate picture of what we know — and what we don’t know — about modern core designs. Please keep in mind that many aspects of this series represent collective best guesses, not certainties.
What’s the difference between a Zen core, a CUDA core, and a Tensor core? Not vaguely — like “one is for graphics, one is for AI” and so on — but specifically, how does each “core” differ in design and operation?
In this multi-part series, we’re going to look in detail at these core types to help bridge the gap between the vague conceptual understanding most of us already have, and the in-depth knowledge we could use to make better sense of hardware behavior across core types.
Here in part 1, we’ll look at the most tangible aspect of a core: what it physically looks like. We’ll put aside the abstract flow charts and design diagrams, and look directly at the silicon itself.
Let’s take a CPU on the left and a GPU on the right and we'll zoom in on the silicon to try to find the things their manufacturers call “cores”. For the CPU, we'll use an AMD Ryzen 5 7600, and for the GPU we'll use an NVIDIA RTX 4090:

Now, these are in no way comparable chips in terms of die area or cost. I picked them because they contain cores that were popular at the time of this recording, and have publicly-available high-quality die shots.
Thankfully, as we'll see, it doesn't matter that much which specific chips we look at. Once we understand what the different types of cores are and what they do, we can apply our knowledge to any CPU or GPU whose layout we know. For now, on the left side we're looking for a Zen 4 core, and on the right side we’re looking for an Ada Lovelace CUDA core and Tensor core.
According to their spec sheets, the 7600 should have 6 Zen 4 cores, and the RTX 4090 should have 16,384 CUDA cores and 512 Tensor cores:

Let’s see if we can find them!
If we remove the cooler and the integrated heat spreader from the chips, this is what they look like:

On the GPU side, there's just one big chip labeled AD102. On the CPU side, it’s not so simple. There are two separate chips on the 7600 module.
The top chip is actually the IO die and doesn't contain any Zen 4 cores. To find a Zen 4 core, we need to look at the bottom chip which is called the Core Complex Die, or CCD:

Now, as we zoom in on these chips, it’s important to remember that the scale is very different. The Zen 4 CCD is only 70 square millimeters. This is much smaller than the monolithic NVIDIA chip that's over 600 square millimeters. The NVIDIA chip is almost nine times larger. Please keep that in mind as we look at these chips in detail.
Although it may not appear so at first, although they differ greatly in size, the high-level layout of these two chips is actually very similar. If we start on the CPU side, we can split the chip into three distinct sections. There are parts on the left and the right that appear to be mirrors of each other, and then there's a band running down the middle.
On the GPU side, we see something similar, but laid out vertically rather than horizontally. The top part and the bottom part mirror each other rather than the left and the right. If we rotate the GPU 90 degrees like this:

we can line up their layouts more directly.
On both chips, the middle section doesn’t contain the cores we’re looking for. It’s occupied by shared resources, such as the last-level cache, or “LLC”. To find our cores, we have to look at the bands on either side, and since they are mirrors of each other, we can simplify things by focusing on just the left band.
If we zoom in, we see that the CPU and GPU have a similar layout once again. From top to bottom, both are made up of what appear to be repeating tiles. On the CPU side, there are four, and and on the GPU side, six:

If the only type of core we were looking for was a Zen 4 core, we could now congratulate ourselves because we have found one. Each of the tiles on the CPU side is actually a Zen 4 core, complete with its dedicated L2 cache.
On the GPU side, however, we’re far from done. NVIDIA doesn’t call these tiles “cores” at all — it calls them Graphics Processing Clusters, or “GPCs”. Measuring the size of the Zen 4 core and the Ada GPC, we can see that the GPC is much larger: nearly seven times larger, in fact!

As you might guess from the term “Cluster”, if we look closely, we can see that the GPC itself is made up of repeating tiles. Although there's a section on the right which contains several non-repeating things like the raster engine, we can see that the rest of the GPC is made up of what appear to be three more repeating tiles.
However, if we zoom in on one the tiles, we see that actually, the tiles themselves each appear to be made up of two mirrored sub-tiles — one on the top and one on the bottom — so in fact there are six sub-tiles in a GPC.
If we measure the size of one of these sub-tiles, we actually find that it matches the area of a Zen 4 core pretty closely: both are around 3.8 mm^2. So are these CUDA or Tensor cores?

Still no. NVIDIA calls these tiles Texture Processing Clusters, or “TPCs”.
TPCs are trickier to divide further because NVIDIA doesn’t tell us much about how these chips are actually laid out. We can guess that the top and bottom are tiled due to how closely they mirror each other, but the middle is less obvious.
Luckily for us, the general consensus on the layout of Ada GPUs is that the middle section doesn’t contain CUDA or Tensor cores. It’s believed to hold things like raytracing cores and texture units, which aren’t what we’re looking for. So we can zoom in on the part of a single TPC that we care about, and ignore the middle section we can’t discern:

When we do that, we see — perhaps unsurprisingly at this point — there's yet more mirroring going on. Although they’re not quite identical, you can see that this part of the TPC is made up of left and right mirrored tiles. That's because, just like before, NVIDIA splits TPCs into two sub-tiles called Streaming Multiprocessors, or “SMs”:

Technically, when NVIDIA says “SM”, they also include its portion of the middle area of the TPC that we weren’t sure how to subdivide. But, thankfully, since we’re only looking for CUDA and Tensor cores here, we can safely ignore that part and zoom in further.
If we measure the part of the SM we’re looking at now, we've arrived at a section of the NVIDIA chip that's significantly smaller than a Zen 4 core. A Zen 4 core is about three times larger than this part of the streaming multiprocessor we're looking at:

But even so, we’re still not at the level of a CUDA or Tensor core!
Based on technical details NVIDIA publishes, we can infer that this section of the streaming multiprocessor probably contains many things in addition to CUDA and Tensor cores — things like L1 caches, schedulers, register files, load/store units, and special function units.
Unfortunately, at this point, we’ve run out of die shot resolution to go further. We can see some vague boundaries, but without more detail, it is impossible to really be sure where the CUDA or Tensor cores are.
We can guess with reasonable certainty that the brighter structures are storage-related. These areas likely contain things like the L1 caches and register files:

But beyond that, all we can really make out are a few faint boundaries.
Now, in theory, if we had money to burn, we could pay a lab to capture a higher—resolution die shot. Or, even better, we could pay them to capture Photon Emission Microscopy videos of the 4090 while it ran some benchmarks we carefully constructed to use specific parts of the chip. That would give us a much better picture of where things are. And hey, if there’s any lab out there that wants to do a collaboration video, definitely don’t hesitate to contact us!
But assuming no one takes us up on that offer, and since we don’t have money to burn, we are left to guesstimate from here. If we measure the silicon area that appears to consist of storage elements, we find it’s around 30%. That leaves 70% of this area to contain everything else: schedulers, load/store units, special function units, CUDA cores, Tensor cores, and so on.
Fortunately, NVIDIA does tell us how many of each main element there are. In this area of the chip, we expect to find 16 load/store units, 4 special function units, 128 CUDA cores, and 4 Tensor cores. Unfortunately, NVIDIA doesn’t give us any information about their relative sizes. To make any estimates, we need to guess two percentages.
First, we need to guess what percentage of the remaining area is taken up by CUDA and Tensor cores, as opposed to everything else. Is it 30% cores? 40%? 50? 60? Then we need to guess how much of the resulting area is taken up by CUDA cores as opposed to Tensor cores. Is it 40%/60%? 50/50? 60/40? For whatever percentages we pick, we can then do the math to determine approximately how big each CUDA and Tensor core is.
Now technically, according to NVIDIA, the 128 CUDA cores are actually separated into two types: 64 of them are floating-point only CUDA cores, and 64 of them are combined floating-point and integer CUDA cores. So if we actually had high enough resolution to see details like that, we might be able to compute two different sizes for CUDA cores themselves. But as we’ve already seen, we’re nowhere near the die shot resolution we’d need for that kind of analysis, so for our low level of accuracy here, it’s sufficient to assume a single average CUDA core size.
So let’s pick some reasonable percentages. Suppose we say a large amount of the remaining area is cores — 60% — and that 70% of that is CUDA cores and 30% is Tensor cores. That would give us a CUDA core size of around 0.003mm^2 and a Tensor core size of around 0.04mm^2. Since we know the size of the Zen 4 core, we can also superimpose how big the two GPU core types would be if they appeared on a Zen 4 CCD. This is roughly how big each core type would be:

Now of course, we really don’t have any way to guess these percentages accurately. We could kick it up to 80% cores, or down to 50% cores, and we have no idea which one is closer. We could say more space went to CUDA cores, or to Tensor cores, than our original ratio. We can play around all day with these percentages, but without better data, we can’t really get more accurate.
We can, however, compute an upper bound. Since the entire area that could contain cores is around 0.88mm^2, if it was entirely devoted to the 128 CUDA cores — which is of course impossible — each CUDA core would be around 0.007mm^2. If it was entirely devoted to the four Tensor cores — also impossible — each Tensor core would be around 0.22mm^2:

Those are the upper bounds on CUDA and Tensor core sizes. We know they each have to be smaller than that — significantly smaller.
Given that, although we couldn’t measure an exact size like we could for the Zen 4 core, we can easily conclude that Tensor cores are quite small compared to a Zen 4 core, and CUDA cores are likely smaller still. Even without knowing what these cores actually do, we now have some intuition about their relative complexity. When people say “Zen 4 core”, they're talking about something way more complicated than what they're talking about when they say CUDA or Tensor core.
As we’ll see, once we understand more about what these different core types actually do, this seemingly strange result actually makes perfect sense. But we’ll have to wait for later parts of this series to see why. For now, it’s time to wrap up our physical core search by checking how many of each core type we think we found on these chips.
To do that, let’s zoom back out just like we zoomed in. As we do, we’ll count the total number of cores we see. Starting here on the GPU side, we know that each one of these streaming multiprocessors has 128 CUDA cores and 4 Tensor cores:

If we zoom out to the TPC level, we know we have two SMs per TPC for a total of 256 CUDA Cores and 8 Tensor cores per Texture Processing Cluster:

Zooming out to the GPC level, we've got six of these Texture Processing Clusters, for a total of 1,536 CUDA cores and 48 Tensor cores per Graphics Processing Cluster. And, we're now up to the highest level of tiling on the chip, which is all the Zen Core Complex Die had. So it's just one Zen 4 core per tile on the CPU side:

If we conclude by zooming out to the entire chip on both sides, we see that the CPU has 8 tiles, and the GPU has 12. This gives us a grand total of 8 Zen 4 cores on the CPU, 18,432 CUDA cores and 576 Tenser cores on the GPU:

Now, if you remember the spec sheet numbers from the beginning of this video, you might think we've done something horribly wrong. The spec sheets said there would be 6 Zen 4 cores, but we counted 8. It said there would be 16,384 CUDA cores, but we counted 18,432. It said there would only be 512 Tensor cores, but we counted 576. We’re over by 2 Zen 4 cores on the CPU side, 2,048 CUDA cores and 64 Tensor cores on the GPU side.
What did we do wrong?
Believe it or not, we actually didn't do anything wrong! This is all by design. One of the ways CPU and GPU vendors increase the yields they get from manufacturing is by designing chips that will still work even if there are some microscopic defects. It’s a common practice to produce chips with more cores physically present than are enabled.
Chips aren’t fabricated individually. They are produced in bulk on giant circular silicon wafers measuring 300mm in diameter. The number of chips that fit on one wafer is directly proportional to the chip’s dimensions. A smaller chip like the 70mm^2 Ryzen CCD can be tiled over 800 times on a wafer. By contrast, the massive 616mm^2 chip in the 4090 can only fit a little over 80 times:

The fabrication process is extremely delicate, and even minor microscopic variations can reduce the quality of the resulting chip. Despite everyone’s best efforts, the quality of the resulting silicon varies somewhat randomly across the wafer, and a small number of unfixable defects per wafer are also inevitable:
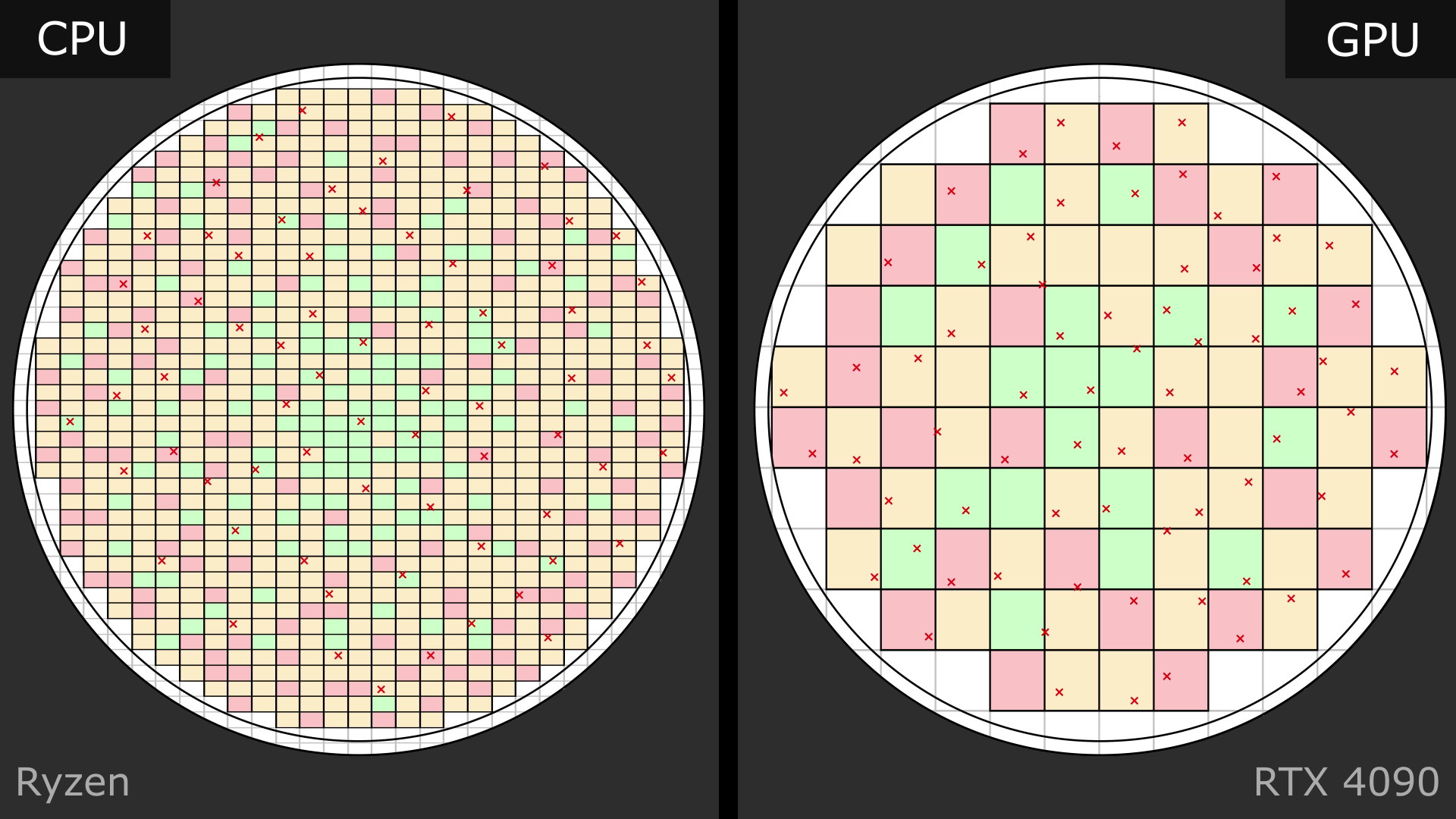
When the wafer is later cut into individual chips, even though they were meant to be identical, each chip will have differing characteristics. Some chips will have no serious defects while others may have several. Some may be able to tolerate higher operating frequencies while others may not.
To avoid wasting silicon, IHVs may therefore take the resulting chips and do what’s called “binning”. Binning is the process of testing individual chips from a wafer to determine how defect-free and performant they are. Chips with few defects that tolerate high operating frequencies are packaged and sold at higher price points as premium SKUs, while chips with more defects or lower operating frequencies are packaged and sold at lower price points.
Given all this, we can easily see why AMD and NVIDIA chips might have more physical cores on them than their spec sheets warrant. In AMD’s case, their strategy with Ryzen core complex dies is to put 8 physical cores on the die, then bin them based on how many of those cores perform up to spec. If all 8 of the cores function properly at spec, the chip could go in a Ryzen 7 7700, which claims 8 CPU cores.
If, on the other hand, there is a defect, or the core cannot perform up to spec, AMD can try selectively disabling part of the chip. Depending on how the chip is designed, they may not be able to disable just one core. AMD doesn’t tell us, so we don’t really know, but the fact that there are vanishingly few 7-core Zen 4 SKUs1 suggest that they may usually disable cores in pairs. But whatever the internal reason, the end result is that many Zen 4 CCDs only have 6 out of the 8 cores enabled, and these are the CCDs that end up being sold in Ryzen 5 7600s like the kind we just looked at:

At this point, we might wonder, what about a Ryzen 9 7900? That has 16 cores. Does it use a different design for the CCD?
Well, when we first looked at the chip without the heat spreader, the placement of the chips did look at bit unusual. If we recall the layout, we can actually see that there is room for a second CCD next to the one we looked at. There just didn’t happen to be anything there on the Ryzen 5 7600 module:

But that wouldn’t be the case on a Ryzen 9 7900. Instead of making a larger die with 16 cores, AMD just uses two dies with 8 cores each. This process of connecting multiple smaller chips is often called a “chiplet” strategy, and it’s been an important competitive advantage for AMD throughout the entire Zen product line.
For the 4090, on the other hand, NVIDIA doesn’t use chiplets. They also don’t appear to bin by functioning core count for their consumer GPUs: NVIDIA 4090s are the only video cards in the lineup to use the AD102 die that we looked at. Other than a recently-released China-specific model designed around export restrictions, all NVIDIA 4090s are spec’d to contain the same number of functioning cores, which is a substantial number of cores less than the number physically present on the AD102 die.
NVIDIA does have a datacenter GPU line called L40 which does use AD102 dies. NVIDIA doesn’t say, but it might be using AD102 dies cut from the same wafer as 4090s, which would suggest that the (relatively few) defect-free AD102 chips per wafer end up on those cards.
To the best of my knowledge, NVIDIA has never explained why there weren’t more consumer GPU bins for the AD102 die. If I had to guess, I would say it has something to do with the very large size of the chip. It’s plausible to assume that, when there are so few chips per wafer, the distribution of defects per individual chip is more uniform, and perhaps wouldn’t yield enough differentiation to make consumer-SKU binning worth it. So although it’s purely speculation on my part, NVIDIA may have decided to pick a safe defect level they felt most chips would clear, and spec’d the 4090s functional core count accordingly.
Specifically, we know that an Ada Streaming Multiprocessor has 128 CUDA cores and 4 Tensor cores. By that ratio, the extra 2048 CUDA cores and 64 Tensor cores might indicate that NVIDIA expects to turn off a total of 16 SMs, which would mean disabling 8 Texture Processing Clusters:

Now, if it were 6 TPCs, that would make have made perfect sense. There are 6 TPCs in each Graphics Processing Cluster. If there’s a defect on the chip, they turn off the GPC containing the defect, and that’s the end of it:

But since the spec sheet indicates 8 TPCs are disabled, not 6, it’s unclear what NVIDIA’s process is. Why do they need to disable two additional TPCs?
Another guess would be that there are many defects per chip. If they expected up to 8 defects per chip, they could be turning off the 8 TPCs that contain the defects:
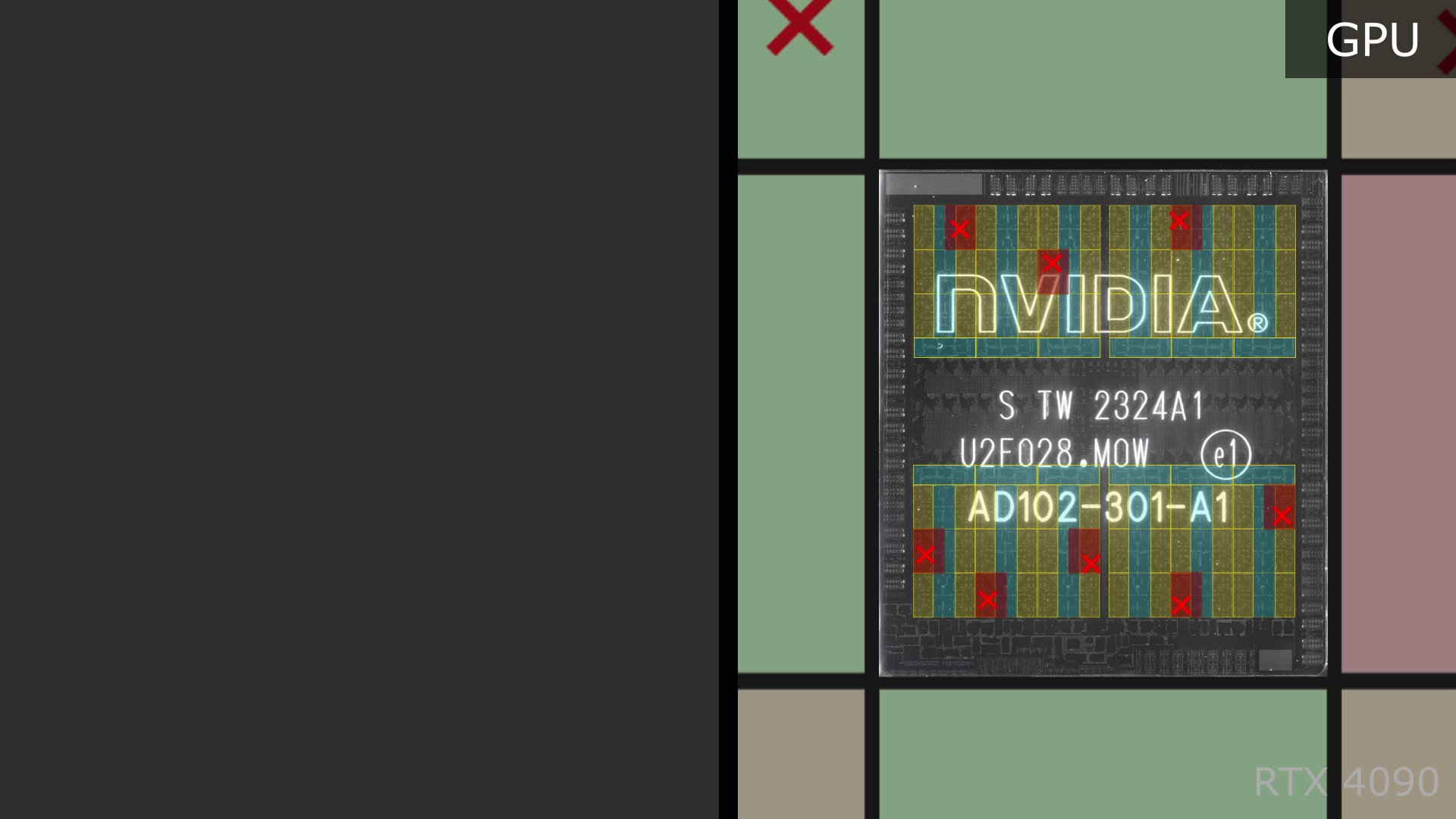
But based on the size of an AD102 die and the expected defects-per-wafer of the TSMC process used to make them, 8 defects on a single AD102 die is extremely unlikely. The median defect count is almost certainly 1, or at most 2, so planning for 8 separate defects is highly implausible.
So unfortunately, yet again, unless NVIDIA wants to share some additional information with us, we really have no way of knowing what’s really going on here. But thankfully, regardless of NVIDIA’s rationale, the end result for us is the same: our core counts were correct. On both the AMD core complex die and the NVIDIA AD102 die, there actually are more physical cores than are enabled when sent to the customer as Ryzen 5 7600s and NVIDIA 4090s. The spec sheets for these products list how many enabled cores you'll get, not how many there are physically on the silicon. Which is, of course, what we would want! Extra cores that are present but can't be used are useless to customers, so it makes sense why spec sheets list enabled rather than physical core counts.

That brings us to the end of Part I. After exploring the silicon as best we could, we’ve seen how easy it was to find a Zen 4 CPU core. They’re large features, and there are only a handful of them on each physical chip.
By contrast, we had a much harder time finding CUDA and Tensor cores. There were features on a GPU that were easy to find, like Graphics Processing Clusters, Texture Processing Clusters, and Streaming Multiprocessors. The Texture Processing Cluster in particular was similarly sized to a Zen 4 CPU core, but it was a much higher-level feature than CUDA or Tensor cores.
In fact, we ran out of die resolution before we even found a CUDA or Tensor core! We were never able to actually see them directly. The best we could do was guesstimate how big they might be based on supplemental technical information from NVIDIA.
So what’s going on here? Why do CPU and GPU “cores” differ in size so dramatically? And why does the GPU seem to have many clearly-visible structural levels before you get to the “cores”, while the CPU does not?
To answer these questions, we need to look at the role these cores play in the execution of CPU and GPU programs — which is exactly what we’ll do in Part 2.
If you enjoyed this article, and would like to receive more like it, you can put your email address in the box below to access both our free and paid subscription options:
Special Thanks
This article and the accompanying video would never have been possible without the amazing work of Fritzchens Fritz, who took the die shots we used to explore these chips and put them in the public domain. I emailed Fritzchens to ask if there was any way we could contribute to their work, either monetarily or by supplying chips for later photography, but I have not heard back. If I do, I will update this post with whatever information I receive!
Also, since silicon analysis is not a core competency of mine, I would not have felt comfortable creating this series without the help of several hardware engineers who donated their time reviewing these materials and correcting errors. As you might expect given the hardware industry’s reputation for secrecy, all wished to remain anonymous, so I cannot thank them by name. But, my heartfelt thanks goes out to all of them just the same — you know who you are, and I could not have done this series without all of you!
Finally, the copious amounts of animation in the video version of this article would not have been possible without Molly Rocket’s own Anna Rettberg, who put together 20 minutes of motion graphics to help make these complex topics easy to visualize.
I originally thought there were literally no 7-core SKUs, but there does appear to be one datacenter SKU that has 7 of 8 cores enabled per CCD: the EPYC 9634. So in some circumstances they do turn off just one core, and it’s unclear why they do not do this in the consumer line. It may have something to do with the reason why the core is turned off, but that is purely speculation.
Wow this is a deep one - fascinating about binning! Wouldn't of thought there was a way to make use of chips with defects..
Thank you for the video!
I have a question. When writing a shader you can use components of a vector in any order (i just found out it is called swizzling https://learn.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-per-component-math). So you can do v.xyz or v.zxy or v.wwxx, or anything, and i heard it is considered a "free" operation. Does it mean that there are wirings for all ordering permutation? It seems like too much it's like 4 + 4^2 + 4^3 + 4^4 = 340, wirings required just for reads, and we have to multiply it by allowed writes. And if it's not that, how would that work? Does it slowdown a regular read when it don't have to do any shifts?